

Translate this page into:
Optimization of Fenoprofen solubility within green solvent through developing a novel and accurate GSO-GPR predictive model
⁎Corresponding author. r.zhrani@tu.edu.sa (Rami M. Alzhrani)
-
Received: ,
Accepted: ,
This article was originally published by Elsevier and was migrated to Scientific Scholar after the change of Publisher.
Peer review under responsibility of King Saud University.
Abstract
Indisputable importance of drug solubility in various industrial perspectives has motivated the scientists to evaluate different techniques to improve it. Fenoprofen is a significant nonsteroidal anti-inflammatory drug (NSAID), that is the orally administered to relieve mild to moderate pain and the unfavorable symptoms of osteoarthritis and rheumatoid arthritis (i.e., inflammation and stiffness). Supercritical fluids (SCFs) belong to a certain type of fluids, in which their temperature and pressure are higher than the critical point. This property allows the CO2SCF to simultaneously possess the characteristics of both a liquid and a gas. The prominent target of this paper is to mathematically develop three predictive models via machine learning (ML) technique to optimize the solubility of Fenoprofen in CO2SCF. In this study, we have 32 data vectors in each dataset, including two input features of pressure and temperature. The output target is solubility, which we are going to model and analyze. Models are constructed through the use of Modular ANN (MANN), Gaussian processes regression (GPR), and the K-Nearest Neighbor technique (KNN) in this body of work. The glowworm swarm optimization (GSO) swarm-based method is utilized in order to carry out the process of model optimization. The root mean squared error (RMSE) rates for GSO-KNN, GSO-MANN, and GSO-GPR are respectively 5.25E-04, 5.46E-04, and 3.01E-05. The aforementioned models were also judged according to a number of other criteria, and since the GSO-GPR model was found to be the most effective according to all of these standards, it is being treated as the conclusive model of this investigation. In addition, the maximum error has been brought down to 5.02E-05 with the help of this model, which has an R2-score of 0.999.
Keywords
Fenoprofen
Optimization
Solubility
Predictive models

1 Introduction
Optimization of efficacious and cost-effective medicines for the treatment of disparate types of acute/chronic illnesses is still a big challenge in pharmacology (Ganesan and Barakat, 2017). Solubility is an important operational parameter in pharmaceutical industry, which its precise measurement is of great importance in drug discovery and development process to improve the pharmacokinetic/therapeutic effects of novel therapeutic agents. Appropriate solubility of an orally-administered drug seems to be significantly vital for enhancing its bioavailability and absorption into the blood circulation (Thapa et al., 2017; Williams et al., 2013). Based on a report, approximately 40 % of innovated drugs in the past and nearly 90 % of the therapeutic medicines in optimization suffer from poor solubility (Kanikkannan, 2018). Therefore, progression of different techniques to optimize and increase the solubility of drugs is a significant activity in drug industry.
Fenoprofen can be considered as a significant orally-administered nonsteroidal anti-inflammatory drug (NSAID), that can be considered as alleviation of inflammation, pain and fever in patients suffering from chronic Musculoskeletal-related disorders like rheumatoid arthritis and osteoarthritis (Traa et al., 2011). Despite some unfavorable side effects like serious kidney failure, this NSAID shows its positive therapeutic properties by the inhibition of cyclooxygenase activity and prostaglandin synthesis (Rajput et al., 2021; Narwariya et al., n.d.; Ridolfo et al., 1979).
In recent decades, disparate approaches like micronization, nanosuspension, spray drying, supercritical fluids and hot melt extrusion have been prosperously applied to optimize the solubility and bioavailability of novel drugs with unacceptable value of solubility (Rasenack and Müller, 2004; Duarte et al., 2011; Madan and Madan, 2012; Feeney et al., 2016). Compared with other prevalently employed techniques, SCFs (especially SCCO2) has achieved more attentions to optimize the solubility and bioavailability of drugs thanks to their brilliant privileges such as low toxicity, environmentally friendly properties, and low cost (Padrela et al., 2018; Ahmad et al., 2019; Bin et al., 2020).
There have been substantial advances in a various range of scientific fields thanks for utilizing of machine learning (ML) models, which are useful tools for extracting information from experimental data. The vast majority of experimental sciences have been impacted by this simple fact (Alpaydin, 2020; Bishop, 2006). One of the important concerns of ML methods is model selection that is, choosing the algorithms and optimizing their important parameters (known as hyper-parameters). In this study, MANN, GPR, and KNN are selected methods, and glowworm swarm optimization (GSO) as a metaheuristic is employed for model selection.
For regression tasks, the GPR employs Gaussian processes (GP). The GP's prior must be given for this to activate. The prior mean is assumed to be constant and equal to 0 or the average of the training data (Rasmussen, 2003; Shi and Choi, 2011). When the data objectives are continuous variables, such as in this study, a Neighbors-based regression can be applied. The label (output) assigned to a query location is calculated by averaging the labels assigned to its closest neighbors (Lall and Sharma, 1996; Song et al., 2017).
For the first time, Krishnanand and Ghose (Krishnanand and Ghose, 2005) used the glowworm swarm optimization (GSO) algorithm to collective robotics. To travel toward a neighbor who shares his luciferin value, each glowworm in this algorithm employs a probabilistic process. Neighboring glowworms are drawn to them (i.e., glowworms that have more luciferin). The motions are dependent only on local information and selected neighbors' connections.
2 Materials
As it mentioned above, the data set consists of 32 rows of data, temperature and pressure being the inputs, and solubility being the output. This data set originates from (Zabihi et al., 2020) and demonstrated in Table 1.
No.
Temperature (K)
Pressure (MPa)
Solubility
1
308
12
8.54E-05
2
308
16
1.63E-04
3
308
20
2.49E-04
4
308
24
3.01E-04
5
308
28
3.95E-04
6
308
32
4.44E-04
7
308
36
5.12E-04
8
308
40
5.87E-04
9
318
12
5.63E-05
10
318
16
1.98E-04
11
318
20
3.55E-04
12
318
24
5.32E-04
13
318
28
7.21E-04
14
318
32
8.56E-04
15
318
36
9.88E-04
16
318
40
1.10E-03
17
328
12
4.15E-05
18
328
16
1.88E-04
19
328
20
4.66E-04
20
328
24
8.11E-04
21
328
28
1.01E-03
22
328
32
1.33E-03
23
328
36
1.84E-03
24
328
40
2.22E-03
25
338
12
2.01E-05
26
338
16
1.66E-04
27
338
20
5.51E-04
28
338
24
1.11E-03
29
338
28
1.74E-03
30
338
32
2.50E-03
31
338
36
3.34E-03
32
338
40
4.20E-03
3 Methods
3.1 Models
The Gaussian process (GP) is a collection of random parameters, a subset of which is associated with Gaussian distributions (Grbić et al., 2013). Covariance and mean functions characterize the GP. Data from the past must be linked in order for Gaussian process regression (GPR) models to work. In contrast to the GD, the GP is over functions. The predictive distribution of the test input is therefore understood by Gaussian process regression models (Rasmussen, 2003).
For GPR, it is not necessary to define the exact fitting function. The data collected in the field may be compared to a multi-dimensional Gaussian distribution sampled at random places (Quinonero-Candela and Rasmussen, 2005; Jiang et al., 2021).
y is exhibited as , , as input matrix and as output.
K illustrates any covariance, that is explained through kernels and their corresponding, m(x) is the mean operator (Wu et al., 2020).
Many regression models employ the K-Nearest Neighbor (KNN) technique, which combines numerous supervised learning models. A basic regression and classification algorithm, this is the model under consideration (Aha et al., 1991; Ribeiro and dos Santos Coelho, 2020). Since it does not generalize from the training examples, it is called a “lazy algorithm.” Indeed, it keeps all of the data collected over the course of the testing process (Song et al., 2017). Using KNN regression is very simple. In order to perform that, it has to be calculated that the amount of neighbors with similar numerical target (Deng, 2020). Another approach is to weight the nearest neighbors to the center. To utilize regression, you use the same distance functions as KNN classification to analysis the samples. This is how you express the Euclidian (Euc_Distance) and the Manhattan distance (Man_Distance). Those equation which are shown below, demonstrate the determination of distance among × and y.
KNN is trained through make a comparison among test data (X,y) and a training data . In regression, the last prediction of y is the mean over its k nearest neighbors' results, as shown in the equation below (Cheng and Ma, 2015; Devroye et al., 1994).
The other used model in this study is modular ANN (MANN). In order to develop MANN, the data points must be separated into multiple clusters, and then each learner is utilized to each cluster separately. In the current work, the fuzzy c-means clustering method is used (Bezdek, 2013; Wang et al., 2006). Soft or crisp clusters may be made. ANN (or equivalent methods) cannot extrapolate beyond the range of data provided for training. Under other conditions, when new data point exceeds the interval of those involved for model training, inaccurate predictions might be predicted. Fig. 1 shows the MANN diagrammatic model in which the training set is divided into four clusters. After input–output pairings are produced, the fuzzy c-means (FCM) technique divides them into four subgroups, and any subset is estimated by an ANN. The modular model's output comes from one of three local models.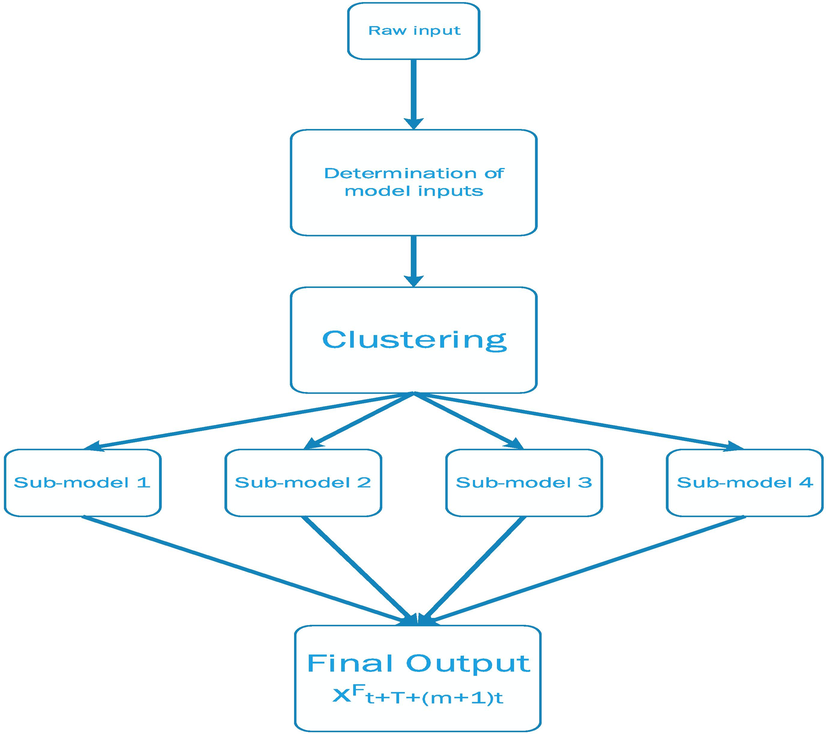
Flowchart of MANN (https://theses.lib.polyu.edu.hk/bitstream/200/5912/1/b23930640.pdf, 2010).
3.2 Model optimization
In this research, we employed glowworm swarm optimization (GSO) approach in order to tune hyper-parameters of models. Krishnanand and Ghose (Krishnanand and Ghose, 2005) created the GSO algorithm, which is an improvement of the ACO. It was driven by the glowworm metaphor and adapted to collaborative robots. Each artificial glowworm or agent in GSO has a local-decision range that lets it light up a two-dimensional work environment. The luciferin level is related to the agent's position's objective value. The brighter agent will fly to a better position. The number of neighbors influences the local decision range. When the density of neighbors is low, the range is widened to discover additional individuals; otherwise, the range is narrowed. The agent's movement direction is always determined by which adjacent individual is chosen. The higher the luciferin level of the neighbor, the greater the magnetism. Finally, most agents will congregate at various sites (Wu et al., 2012).
All individuals (glowworms) have the identical value of luciferin, however it changes according on their response of function. The luciferin value at that site is well proportioned to the observed value of the sensor profile. Every glowworm increases its previous level of luciferin (Manimaran and Selladurai, 2014). Simultaneously, the glowworm's luciferin level is deducted from the prior luminescence measurement to imitate luminosity degradation. The rule of luciferin updating is:
In the above equation, li(t) is the level of luciferin for the individual I based on the time t, ρ stands for the luciferin decay constant 0 < ρ < 1, γ reflects the luciferin enhancement constant, moreover, Ji denotes the objective function at individual i's position based on the time time, t.
The chance of traveling toward an adjacent j for each glowworm I is determined by (Muller, 2007):
Where stands for the neighborhood for the glowworm i in iteration t. di,j(t) shows the distance of individuals i and j at iteration or time t, moreover, rid(t) stands for the variable neighborhood range amalgamated via individuals i at time t. Assume that individual i choose an individual j ∈ Ni(t) with pij(t) determined by the above equation. Then, motions of glowworms might be expressed as (He, 2022):
In this equation, s shows the step size described above and ∥∥ reflects the Euclidean norm operator.
The rule for neighborhood range updating: We connect with each individual i a neighborhood which radial range rid is naturally dynamic 0 < rid < rs.rs represents the radial range of the luciferin sensor (Krishnanand, 2009).
The neighborhood range is difficult to establish at a value that works well for diverse function landscapes since we suppose that a priori knowledge about the fitness function is unknown. A specified neighborhood range rd, for example, would perform better on fitness functions where the optimum inter-peak distance is greater than rd than on those where it is smaller than rd. This optimization algorithm employs an adaptive neighborhood range to locate numerous peaks in a multimodal function landscape. The following rule may be observed to significantly boost performance (Abdullah, 2021; Zhou et al., 2013; Krishnanand, 2009):
Where β stands for a constant value and nt is utilized to control the quantity of neighbors. The workflow of GSO is displayed in Fig. 2.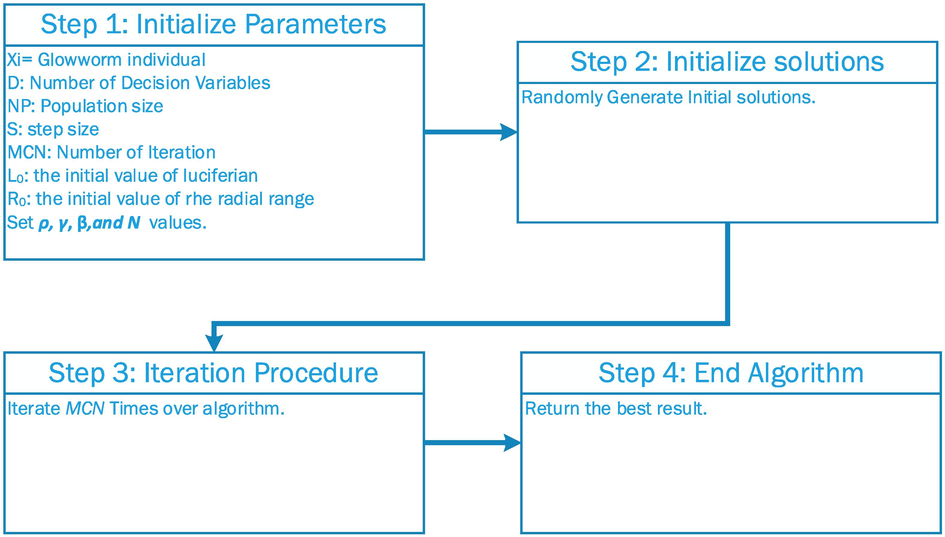
The Flowchart of the GSO algorithm.
3.3 Performance evaluation
In our study, the accuracy of the utilized regression models are assessed using the criteria listed below. The following are the definitions of metrics:
Here, is the expected (observed) solubility, is the forecasted solubility, and N is the quntity of data points.
4 Results
After implementation of the introduced models, their hyper-parameters were tuned using the GSO algorithm. For this purpose, multiple values for the number of iterations are possible and have a direct impact on the performance of models. In Fig. 3, the impact of this value is shown with R2-socre. Based on this chart, the number of iterations is set at 45 for GPR and 60 for two other models.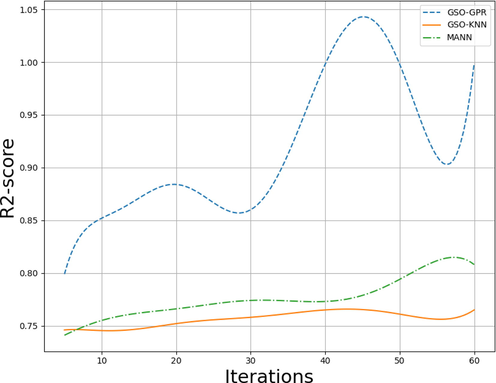
Number of iterations vs R2-score.
After optimizing hyper-parameters, final models are obtained and assessed via standard metrics. The final results are shown in Table 2. Also, a visual comparison of expected and estimated targets is shown in Figs. 4, 5, and 6. These facts and figures lead us to select GSO-GPR as the most accurate, the most general and the best model for this research due to its higher R2-Score and lower RMSE.
Models
MSE
RMSE
MAPE
R2-Score
Max Error
GSO-KNN
2.75E-07
5.25E-04
2.86E + 00
0.767
1.14E-03
GSO-MANN
2.98E-07
5.46E-04
1.56E + 00
0.808
1.03E-03
GSO-GPR
9.11E-10
3.01E-05
6.49E-02
0.999
5.02E-05
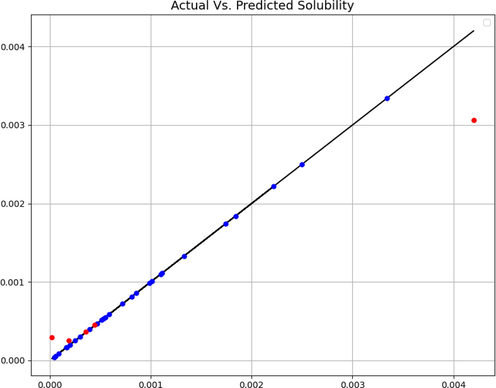
Expected and predicted values (GSO-KNN).
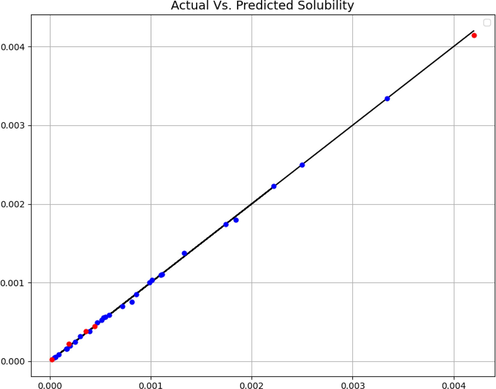
Expected and predicted values (GSO-GPR).
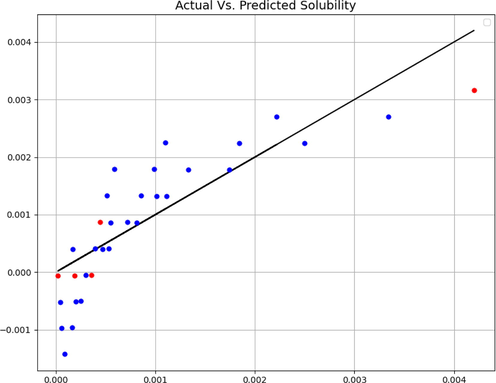
Expected and predicted values (GSO-MANN).
Figs. 7 and 8 respectively demonstrates 2D schemes to evaluate the influences of two important inlet parameters including temperature and pressure on the solubility amount of Fenoprofen in SCCO2 solvent. Glancing at the figures implies this reality that by increasing the pressure of system, the solubility of Fenoprofen NSAID in SCCO2 solvent enhances substantially because of increasing the molecular compaction and consequently enhancing in the density of solvent, which approaches the characteristics of the SCCO2 solvent to liquid phase. Increase in the density of solvent has a direct relationship with the solvating power of SCCO2 solvent. For evaluating the influence of temperature, the variation of sublimation pressure and density ate the pressures greater and lower than the cross-over pressure (COP) seems to be important. Applying higher pressure which is more than COP, an increasing in the temperature be able to improve the sublimation pressure while declines the density of SCCO2 system. But the effect of sublimation pressure enhancement is stronger than the effect of decreased density on the solubility of Fenoprofen in SCCO2 solvent. Therefore, increase in temperature at pressures higher than COP modify the drug solubility. When the pressure of the solvent system is lower than the COP, the negative influence of density reduction is higher than the desirable influence of sublimation pressure. Moreover, increase in temperature at pressures greater than COP significantly reduces the solubility of Fenoprofen in SCCO2 solvent.(See Fig. 9.).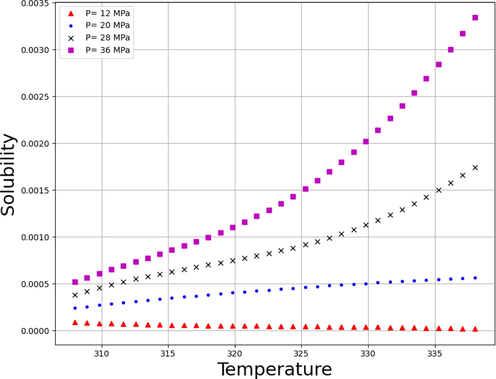
Tendency of temperature.
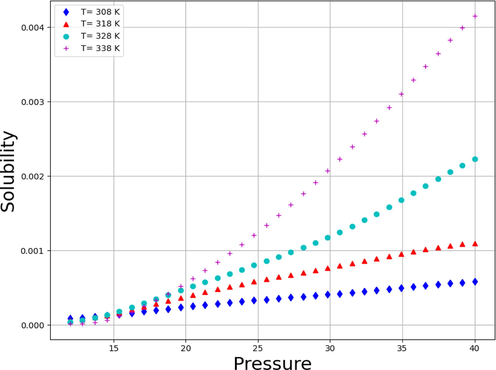
Tendency of pressure.
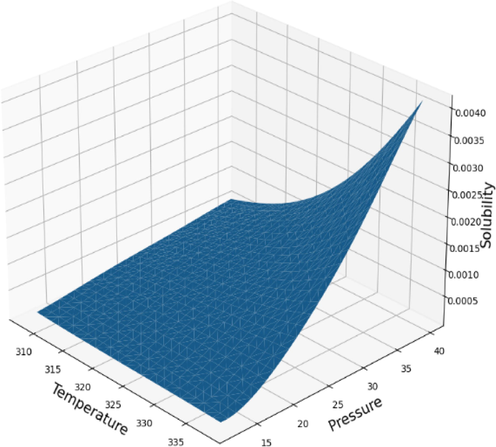
Final model prediction surface (GSO-GPR).
5 Conclusion
Poor solubility of the majority of novel orally administered therapeutic medicines have motivated the researchers and scientists to find various ways to improve the solubility. In recent decades, the industrial-based application of SCFs (such as SCCO2) to improve the solubility of drugs has found greater attentions compared to other conventional techniques due to their non-poisonous, eco-friendly and cost-effective nature. In this research paper, machine learning (ML) technique has been employed to develop accurate mathematical models to estimate the solubility of Fenoprofen NSAID in SCCO2 solvent. To do this work, Modular ANN (MANN), Gaussian Process Regression (GPR), and K-Nearest Neighbor Technique (KNN) are employed to make models. Model optimization is performed employing GSO swarm-based algorithm. GSO-KNN, GSO-MANN, and GSO-GPR have RMSE error rates of 5.25E-04, 5.46E-04, and 3.01E-05, respectively. In terms of RMSE they have 5.25E-04, 5.46E-04, and 3.01E-05 error rates. MAPE of GSO-KNN is 2.86E + 00, it is 1.56E + 00 for GSO-MANN, and the best one is 6.49E-02 for GSO-GPR. The mentioned models were also evaluated with other criteria, and the GSO-GPR model was found to have the best efficiency in all criteria, so this model is considered the final model of this research. GSO-GPR shows R2 score of 0.999, then the max error has been reduced to 5.02E-05.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Cocktail parity problem solution based on modified blind extraction technique. Indonesian journal of electrical engineering and computer science 2021
- [CrossRef] [Google Scholar]
- Introduction to machine learning. MIT press; 2020.
- Pattern recognition with fuzzy objective function algorithms. Springer Science & Business Media; 2013.
- Supercritical fluid technology and its pharmaceutical applications: a revisit with two decades of progress. Indian J. Pharma. Edu. Res.. 2020;54:1-11.
- [Google Scholar]
- A non-linear case-based reasoning approach for retrieval of similar cases and selection of target credits in LEED projects. Build. Environ.. 2015;93:349-361.
- [Google Scholar]
- Machine learning on density and elastic property of oxide glasses driven by large dataset. J. Non-Cryst. Solids. 2020;529:119768
- [Google Scholar]
- On the strong universal consistency of nearest neighbor regression function estimates. Ann. Statist. 1994:1371-1385.
- [Google Scholar]
- Overcoming poor bioavailability through amorphous solid dispersions. Ind. Pharm.. 2011;30:4-6.
- [Google Scholar]
- 50 years of oral lipid-based formulations: provenance, progress and future perspectives. Adv. Drug Deliv. Rev.. 2016;101:167-194.
- [Google Scholar]
- Solubility: a speed–breaker on the drug discovery highway. MOJ Bioequiv. Availab.. 2017;3:56-58.
- [Google Scholar]
- Stream water temperature prediction based on Gaussian process regression. Expert Syst. Appl.. 2013;40:7407-7414.
- [Google Scholar]
- On rough set based fuzzy clustering for graph data-https://doi.org/10.1007/s13042-022-01607-6. international journal of machine learning and cybernetics 2022
- [Google Scholar]
- POLYTECHNIC UNIVERSITY 2010
- [Google Scholar]
- Prediction of gas-liquid two-phase choke flow using Gaussian process regression. Flow Meas. Instrum.. 2021;81:102044
- [Google Scholar]
- Technologies to improve the solubility, dissolution and bioavailability of poorly soluble drugs. J. Anal. Pharm. Res. 2018;7:00198.
- [Google Scholar]
- Glowworm swarm optimization for simultaneous capture of multiple local optima of multimodal functions. Swarm Intelligence 2009
- [CrossRef] [Google Scholar]
- Detection of multiple source locations using a glowworm metaphor with applications to collective robotics. In: Proceedings 2005 IEEE Swarm Intelligence Symposium, 2005. SIS 2005. IEEE; 2005. p. :84-91.
- [Google Scholar]
- A nearest neighbor bootstrap for resampling hydrologic time series. Water Resour. Res.. 1996;32:679-693.
- [Google Scholar]
- Hot melt extrusion and its pharmaceutical applications. Asian J. Pharm. Sci.. 2012;7
- [Google Scholar]
- Glowworm swarm optimisation algorithm for nonlinear fixed charge transportation problem in a single stage supply chain network. Int. J. Logist. Econ. Globalis.. 2014;6:42-55.
- [Google Scholar]
- Supercritical carbon dioxide-based technologies for the production of drug nanoparticles/nanocrystals–a comprehensive review. Adv. Drug Deliv. Rev.. 2018;131:22-78.
- [Google Scholar]
- A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res.. 2005;6:1939-1959.
- [Google Scholar]
- S.S. Rajput, D. Marothia, D. Sharma, A REVIEW ON FORMULATION AND EVALUATIONOF ORODISPERSIBLE BILAYER TABLET CONTAINING FENOPROFEN CALCIUM, (2021).
- Micron-size drug particles: common and novel micronization techniques. Pharm. Dev. Technol.. 2004;9:1-13.
- [Google Scholar]
- Gaussian processes in machine learning. In: Summer School on Machine Learning. Springer; 2003. p. :63-71.
- [Google Scholar]
- Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft Comput.. 2020;86:105837
- [Google Scholar]
- S.S. Narwariya, S. Jain, A. singh Jadon, M. Soni, A Review on Development and Evaluation of Mouth Dissolving Anti-inflammatory Tablet Containing Fenoprofen.
- Gaussian process regression analysis for functional data. CRC Press; 2011.
- An efficient instance selection algorithm for k nearest neighbor regression. Neurocomputing. 2017;251:26-34.
- [Google Scholar]
- Analysis and optimization of drug solubility to improve pharmacokinetics. J. Pharma. Investig.. 2017;47:95-110.
- [Google Scholar]
- Single dose oral fenoprofen for acute postoperative pain in adults. Cochrane Database Syst. Rev. 2011
- [Google Scholar]
- Forecasting daily streamflow using hybrid ANN models. J. Hydrol.. 2006;324:383-399.
- [Google Scholar]
- Strategies to address low drug solubility in discovery and development. Pharmacol. Rev.. 2013;65:315-499.
- [Google Scholar]
- C. Wu, Z. Khan, S. Ioannidis, J.G. Dy, Deep Kernel Learning for Clustering∗, in: Proceedings of the 2020 SIAM International Conference on Data Mining, SIAM, 2020, pp. 640-648.
- The improvement of glowworm swarm optimization for continuous optimization problems. Expert Syst. Appl.. 2012;39:6335-6342.
- [Google Scholar]
- Experimental solubility measurements of fenoprofen in supercritical carbon dioxide. J. Chem. Eng. Data. 2020;65:1425-1434.
- [Google Scholar]
- A glowworm swarm optimization algorithm based tribes. Appl. Math. Information Sci.. 2013;7:537-541.
- [Google Scholar]




